Profiling
Speed
Why is OCaml fast? Indeed, step back and ask is OCaml fast? How can we
make programs faster? In this chapter we'll look at what actually
happens when you compile your OCaml programs down to machine code. This
will help in understanding why OCaml is not just a great language for
programming, but is also a very fast language indeed. And it'll help you
to help the compiler write better machine code for you. It's also (I
believe anyway) a good thing for programmers to have some idea of what
happens between you typing ocamlopt and getting a binary you can run.
But you will need to know some assembler to get the most out of this section. Don't be afraid! I'll help you out by translating the assembler into a C-like pseudocode (after all C is just a portable assembly language).
Basics of Assembly Language
The examples I give in this chapter are all compiled on an x86 Linux machine. The x86 is, of course, a 32 bit machine, so an x86 "word" is 4 bytes (= 32 bits) long. At this level OCaml deals mostly with word-sized objects, so you'll need to remember to multiply by four to get the size in bytes.
To refresh your memory, the x86 has only a small number of general
purpose registers, each of which can store one word. The Linux assembler
puts % in front of register names. The registers are: %eax, %ebx,
%ecx, %edx, %esi, %edi, %ebp (special register used for stack
frames), and %esp (the stack pointer).
The Linux assembler (in common with other Unix assemblers, but opposite to MS-derived assemblers) writes moves to and from registers/memory as:
movl from, to
So movl %ebx, %eax means "copy the contents of register %ebx into
register %eax" (not the other way round).
Almost all of the assembly language that we will look at is going to be
dominated not by machine code instructions like movl but by what are
known as assembler directives. These directives begin
with a . (period) and they literally direct the assembler to do
something. Here are the common ones for the Linux assembler:
.text
Text is the Unix way of saying "program code". The text segment
simply means the part of the executable where program code is stored.
The .text directive switches the assembler so it starts writing into
the text segment.
.data
Similarly, the .data directive switches the assembler so it starts
writing into the data segment (part) of the executable.
.globl foo
foo:
This declares a global symbol called foo. It means the address of the
next thing to come can be named foo. Writing just foo: without the
preceding .globl directive declares a local symbol (local to just the
current file).
.long 12345
.byte 9
.ascii "hello"
.space 4
.long writes a word (4 bytes) to the current segment. .byte writes a
single byte. .ascii writes a string of bytes (NOT nul-terminated).
.space writes the given number of zero bytes. Normally you use these
in the data segment.
The “hello, world” Program
Enough assembler. Put the following program into a file called
smallest.ml:
print_string "hello, world\n"
And compile it to a native code executable using:
ocamlopt -S smallest.ml -o smallest
The -S (capital S) tells the compiler to leave the assembly language
file (called smallest.s - lowercase s) instead of deleting it.
Here are the edited highlights of the smallest.s file with my comments
added. First of all the data segment:
.data
.long 4348 ; header for string
.globl Smallest__1
lest__1:
.ascii "hello, world\12" ; string
.space 2 ; padding ..
.byte 2 ; .. after string
Next up the text (program code) segment:
.text
.globl Smallest__entry ; entry point to the program
lest__entry:
; this is equivalent to the C pseudo-code:
; Pervasives.output_string (stdout, &Smallest__1)
movl $Smallest__1, %ebx
movl Pervasives + 92, %eax ; Pervasives + 92 == stdout
call Pervasives__output_string_212
; return 1
movl $1, %eax
ret
In C everything has to be inside a function. Think about how you can't
just write printf ("hello, world\n"); in C, but instead you have to
put it inside main () { ... }. In OCaml you are allowed to have
commands at the top level, not inside a function. But when we translate
this into assembly language, where do we put those commands? There needs
to be some way to call those commands from outside, so they need to be
labelled in some way. As you can see from the code snippet, OCaml solves
this by taking the filename (smallest.ml), capitalising it and adding
__entry, thus making up a symbol called Smallest__entry to refer to
the top level commands in this file.
Now look at the code that OCaml has generated. The original code said
print_string "hello, world\n", but OCaml has instead compiled the
equivalent of Pervasives.output_string stdout "hello, world\n". Why?
If you look into pervasives.ml you'll see why:
let print_string s = output_string stdout s
OCaml has inlined this function. Inlining - taking a function and expanding it from its definition - is sometimes a performance win, because it avoids the overhead of an extra function call, and it can lead to more opportunities for the optimiser to do its thing. Sometimes inlining is not good, because it can lead to code bloating, and thus destroys the good work done by the processor cache (and besides function calls are actually not very expensive at all on modern processors). OCaml will inline simple calls like this, because they are essentially risk free, almost always leading to a small performance gain.
What else can we notice about this? The calling convention seems to be
that the first two arguments are passed in the %eax and %ebx
registers respectively. Other arguments are probably passed on the
stack, but we'll see about that later.
C programs have a simple convention for storing strings, known as
ASCIIZ. This just means that the string is stored in ASCII, followed
by a trailing NUL (\0) character. OCaml stores strings in a different
way, as we can see from the data segment above. This string is stored
like this:
4 byte header: 4348
the string: h e l l o , SP w o r l d \n
padding: \0 \0 \002
Firstly the padding brings the total length of the string up to a whole number of words (4 words, 16 bytes in this example). The padding is carefully designed so that you can work out the actual length of the string in bytes, provided that you know the total number of words allocated to the string. The encoding for this is unambiguous (which you can prove to yourself).
One nice feature of having strings with an explicit length is that you
can represent strings containing ASCII NUL (\0) characters in them,
something which is difficult to do in C. However, the flip side is that
you need to be aware of this if you pass an OCaml string to some C
native code: if it contains ASCII NUL, then the C str* functions will
fail on it.
Secondly we have the header. Every boxed (allocated) object in OCaml has a header which tells the garbage collector about how large the object is in words, and something about what the object contains. Writing the number 4348 in binary:
length of the object in words: 0000 0000 0000 0000 0001 00 (4 words)
color (used by GC): 00
tag: 1111 1100 (String_tag)
See /usr/include/caml/mlvalues.h for more information about
the format of heap allocated objects in OCaml.
One unusual thing is that the code passes a pointer to the start of the
string (ie. the word immediately after the header) to
Pervasives.output_string. This means that output_string must
subtract 4 from the pointer to get at the header to determine the length
of the string.
What have I missed out from this simple example? Well, the text segment
above is not the whole story. It would be really nice if OCaml
translated that simple hello world program into just the five lines of
assembler shown above. But there is the question of what actually calls
Smallest__entry in the real program. For this OCaml includes a whole
load of bootstrapping code which does things like starting up the
garbage collector, allocating and initialising memory, calling
initialisers in libraries and so on. OCaml links all of this code
statically to the final executable, which is why the program I end up
with (on Linux) weighs in at a portly 95,442 bytes. Nevertheless the
start-up time for the program is still unmeasurably small (under a
millisecond), compared to several seconds for starting up a reasonable
Java program and a second or so for a Perl script.
Tail Recursion
We mentioned in chapter 6 that OCaml can turn tail-recursive function calls into simple loops. Is this actually true? Let's look at what simple tail recursion compiles to:
let rec loop () =
print_string "I go on forever ...";
loop ()
let () = loop ()
The file is called tail.ml, so following OCaml's usual procedure for
naming functions, our function will be called Tail__loop_nnn (where
nnn is some unique number which OCaml appends to distinguish
identically named functions from one another).
Here is the assembler for just the loop function defined above:
.text
.globl Tail__loop_56
Tail__loop_56:
.L100:
; Print the string
movl $Tail__2, %ebx
movl Pervasives + 92, %eax
call Pervasives__output_string_212
.L101:
; The following movl is in fact obsolete:
movl $1, %eax
; Jump back to the .L100 label above (ie. loop forever)
jmp .L100
So that's pretty conclusive. Calling Tail__loop_56 will first print
the string, and then jump back to the top, then print the string, and
jump back, and so on forever. It's a simple loop, not a recursive
function call, so it doesn't use any stack space.
Digression: Where Are the Types?
OCaml is statically typed as we've said before on many occasions, so at
compile time, OCaml knows that the type of loop is unit -> unit. It
knows that the type of "hello, world\n" is string. It doesn't make
any attempt to communicate this fact to the output_string function.
output_string is expecting a channel and a string as arguments,
and indeed that's what it gets. What would happen if we passed, say, an
int instead of a string?
This is essentially an impossible condition. Because OCaml knows the
types at compile time, it doesn't need to deal with types or check types
at run time. There is no way, in pure OCaml, to "trick" the compiler
into generating a call to Pervasives.output_string stdout 1. Such an
error would be flagged at compile time, by type inference, and so could
never be compiled.
The upshot is that by the time we have compiled OCaml code to assembler type information mostly isn't required, certainly in the cases we've looked at above where the type is fully known at compile time, and there is no polymorphism going on.
Fully knowing all your types at compile time is a major performance win
because it totally avoids any dynamic type checking at run time. Compare
this to a Java method invocation for example: obj.method (). This is
an expensive operation because you need to find the concrete class that
obj is an instance of, and then look up the method, and you need to do
all of this potentially every time you call any method. Casting
objects is another case where you need to do a considerable amount of
work at run time in Java. None of this is allowed with OCaml's static
types.
Polymorphic Types
As you might have guessed from the discussion above, polymorphism, which is where the compiler doesn't have a fully known type for a function at compile time, might have an impact on performance. Suppose we require a function to work out the maximum of two integers. Our first attempt is:
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
Simple enough, but recall that the > (greater than) operator in OCaml
is polymorphic. It has type 'a -> 'a -> bool, and this means that the
max function we defined above is going to be polymorphic:
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
This is indeed reflected in the code that OCaml generates for this function, which is pretty complex:
.text
.globl Max__max_56
Max__max_56:
; Reserve two words of stack space.
subl $8, %esp
; Save the first and second arguments (a and b) on the stack.
movl %eax, 4(%esp)
movl %ebx, 0(%esp)
; Call the C "greaterthan" function (in the OCaml library).
pushl %ebx
pushl %eax
movl $greaterthan, %eax
call caml_c_call
.L102:
addl $8, %esp
; If the C "greaterthan" function returned 1, jump to .L100
cmpl $1, %eax
je .L100
; Returned 0, so get argument a which we previously saved on
; the stack and return it.
movl 4(%esp), %eax
addl $8, %esp
ret
; Returned 1, so get argument b which we previously saved on
; the stack and return it.
.L100:
movl 0(%esp), %eax
addl $8, %esp
ret
Basically the > operation is done by calling a C function from the OCaml library. This is obviously not going to be very efficient, nothing like as efficient as if we could generate some quick inline assembly language for doing the >.
This is not a complete dead loss by any means. All we need to do is to
hint to the OCaml compiler that the arguments are in fact integers. Then
OCaml will generate a specialised version of max which only works on
int arguments:
# let max (a : int) (b : int) =
if a > b then a else b;;
val max : int -> int -> int = <fun>
Here is the assembly code generated for this function:
.text
.globl Max_int__max_56
Max_int__max_56:
; Single assembly instruction "cmpl" for performing the > op.
cmpl %ebx, %eax
; If %ebx > %eax, jump to .L100
jle .L100
; Just return argument a.
ret
; Return argument b.
.L100:
movl %ebx, %eax
ret
That's just 5 lines of assembler, and is about as simple as you can make it.
What about this code:
# let max a b =
if a > b then a else b;;
val max : 'a -> 'a -> 'a = <fun>
# let () = print_int (max 2 3);;
3
Is OCaml going to be smart enough to inline the max function and
specialise it to work on integers? Disappointingly the answer is no.
OCaml still has to generate the external Max.max symbol (because this
is a module, and so that function might be called from outside the
module), and it doesn't inline the function.
Here's another variation:
# let max a b =
if a > b then a else b in
print_int (max 2 3);;
3
- : unit = ()
Disappointingly although the definition of max in this code is local
(it can't be called from outside the module), OCaml still doesn't
specialise the function.
Lesson: if you have a function which is unintentionally polymorphic then you can help the compiler by specifying types for one or more of the arguments.
The Representation of Integers, Tag Bits, Heap-Allocated Values
There are a number of peculiarities about integers in OCaml. One of these is that integers are 31 bit entities, not 32 bit entities. What happens to the "missing" bit?
Write this to int.ml:
print_int 3
and compile with ocamlopt -S int.ml -o int to generate assembly
language in int.s. Recall from the discussion above that we are
expecting OCaml to inline the print_int function as
output_string (string_of_int 3), and examining the assembly language
output we can see that this is exactly what OCaml does:
.text
.globl Int__entry
Int__entry:
; Call Pervasives.string_of_int (3)
movl $7, %eax
call Pervasives__string_of_int_152
; Call Pervasives.output_string (stdout, result_of_previous)
movl %eax, %ebx
movl Pervasives + 92, %eax
call Pervasives__output_string_212
The important code is movl $7, %eax. It shows two things: Firstly the
integer is unboxed (not allocated on the heap), but is instead passed
directly to the function in the register %eax. This is fast. But
secondly we see that the number being passed is 7, not 3.
This is a consequence of the representation of integers in OCaml. The bottom bit of the integer is used as a tag - we'll see what for next. The top 31 bits are the actual integer. The binary representation of 7 is 111, so the bottom tag bit is 1 and the top 31 bits form the number 11 in binary = 3. To get from the OCaml representation to the integer, divide by two and round down.
Why the tag bit at all? This bit is used to distinguish between integers
and pointers to structures on the heap, and the distinction is only
necessary if we are calling a polymorphic function. In the case above,
where we are calling string_of_int, the argument can only ever be an
int and so the tag bit would never be consulted. Nevertheless, to
avoid having two internal representations for integers, all integers in
OCaml carry around the tag bit.
A bit of background about pointers is required to understand why the tag bit is really necessary, and why it is where it is.
In the world of RISC chips like the Sparc, MIPS and Alpha, pointers have to be word-aligned. So on the older 32 bit Sparc, for example, it's not possible to create and use a pointer which isn't aligned to a multiple of 4 (bytes). Trying to use one generates a processor exception, which means basically your program segfaults. The reason for this is just to simplify memory access. It's just a lot simpler to design the memory subsystem of a CPU if you only need to worry about word-aligned access.
For historical reasons (because the x86 is derived from an 8 bit chip), the x86 has supported unaligned memory access, although if you align all memory accesses to multiples of 4, then things go faster.
Nevertheless, all pointers in OCaml are aligned - ie. multiples of 4 for 32 bit processors, and multiples of 8 for 64 bit processors. This means that the bottom bit of any pointer in OCaml will always be zero.
So you can see that by looking at the bottom bit of a register, you can immediately tell if it stores a pointer ("tag" bit is zero), or an integer (tag bit set to one).
Remember our polymorphic > function which caused us so much trouble in
the previous section? We looked at the assembler and found out that
OCaml compiles a call to a C function called greaterthan whenever it
sees the polymorphic form of >. This function takes two arguments, in
registers %eax and %ebx. But greaterthan can be called with
integers, floats, strings, opaque objects ... How does it know what
%eax and %ebx point to?
It uses the following decision tree:
- Tag bit is one: compare the two integers and return.
- Tag bit is zero:
%eaxand%ebxmust point at two heap-allocated memory blocks. Look at the header word of the memory blocks, specifically the bottom 8 bits of the header word, which tag the content of the block.- String_tag: Compare two strings.
- Double_tag: Compare two floats.
- etc.
Note that because > has type 'a -> 'a -> bool, both arguments must
have the same type. The compiler should enforce this at compile time. I
would assume that greaterthan probably contains code to sanity-check
this at run time however.
Floats
Floats are, by default, boxed (allocated on the heap). Save this as
float.ml and compile it with ocamlopt -S float.ml -o float:
print_float 3.0
The number is not passed directly to string_of_float in the %eax
register as happened above with ints. Instead, it is created statically
in the data segment:
.data
.long 2301
.globl Float__1
Float__1:
.double 3.0
and a pointer to the float is passed in %eax instead:
movl $Float__1, %eax
call Pervasives__string_of_float_157
Note the structure of the floating point number: it has a header (2301), followed by the 8 byte (2 word) representation of the number itself. The header can be decoded by writing it as binary:
Length of the object in words: 0000 0000 0000 0000 0000 10 (8 bytes)
Color: 00
Tag: 1111 1101 (Double_tag)
string_of_float isn't polymorphic, but suppose we have a polymorphic
function foo : 'a -> unit taking one polymorphic argument. If we call
foo with %eax containing 7, then this is equivalent to foo 3,
whereas if we call foo with %eax containing a pointer to Float__1
above, then this is equivalent to foo 3.0.
Arrays
I mentioned earlier that one of OCaml's targets was numerical computing.
Numerical computing does a lot of work on vectors and matrices, which
are essentially arrays of floats. As a special hack to make this go
faster, OCaml implements arrays of unboxed floats. This
means that in the special case where we have an object of type
float array (array of floats), OCaml stores them the same way as in C:
double array[10];
... instead of having an array of pointers to ten separately allocated floats on the heap.
Let's see this in practice:
let a = Array.create 10 0.0;;
for i = 0 to 9 do
a.(i) <- float_of_int i
done
I'm going to compile this code with the -unsafe option to remove
bounds checking (simplifying the code for our exposition here). The
first line, which creates the array, is compiled to a simple C call:
pushl $Arrayfloats__1 ; Boxed float 0.0
pushl $21 ; The integer 10
movl $make_vect, %eax ; Address of the C function to call
call caml_c_call
; ...
movl %eax, Arrayfloats ; Store the resulting pointer to the
; array at this place on the heap.
The loop is compiled to this relatively simple assembly language:
movl $1, %eax ; Let %eax = 0. %eax is going to store i.
cmpl $19, %eax ; If %eax > 9, then jump out of the
jg .L100 ; loop (to label .L100 at the end).
.L101: ; This is the start of the loop body.
movl Arrayfloats, %ecx ; Address of the array to %ecx.
movl %eax, %ebx ; Copy i to %ebx.
sarl $1, %ebx ; Remove the tag bit from %ebx by
; shifting it right 1 place. So %ebx
; now contains the real integer i.
pushl %ebx ; Convert %ebx to a float.
fildl (%esp)
addl $4, %esp
fstpl -4(%ecx, %eax, 4) ; Store the float in the array at the ith
; position.
addl $2, %eax ; i := i + 1
cmpl $19, %eax ; If i <= 9, loop around again.
jle .L101
.L100:
The important statement is the one which stores the float into the array. It is:
fstpl -4(%ecx, %eax, 4)
The assembler syntax is rather complex, but the bracketed expression
-4(%ecx, %eax, 4) means "at the address %ecx + 4*%eax - 4". Recall
that %eax is the OCaml representation of i, complete with tag bit, so
it is essentially equal to i*2+1, so let's substitute that and
multiply it out:
%ecx + 4*%eax - 4
= %ecx + 4*(i*2+1) - 4
= %ecx + 4*i*2 + 4 - 4
= %ecx + 8*i
(Each float in the array is 8 bytes long.)
So arrays of floats are unboxed, as expected.
Partially Applied Functions and Closures
How does OCaml compile functions which are only partially applied? Let's compile this code:
Array.map ((+) 2) [|1; 2; 3; 4; 5|]
If you recall the syntax, [| ... |] declares an array (in this case an
int array), and ((+) 2) is a closure - "the function which adds 2 to
things".
Compiling this code reveals some interesting new features. Firstly the code which allocates the array:
movl $24, %eax ; Allocate 5 * 4 + 4 = 24 bytes of memory.
call caml_alloc
leal 4(%eax), %eax ; Let %eax point to 4 bytes into the
; allocated memory.
All heap allocations have the same format: 4 byte header + data. In this case the data is 5 integers, so we allocate 4 bytes for the header plus 5 * 4 bytes for the data. We update the pointer to point at the first data word, ie. 4 bytes into the allocated memory block.
Next OCaml generates code to initialise the array:
movl $5120, -4(%eax)
movl $3, (%eax)
movl $5, 4(%eax)
movl $7, 8(%eax)
movl $9, 12(%eax)
movl $11, 16(%eax)
The header word is 5120, which if you write it in binary means a block containing 5 words, with tag zero. The tag of zero means it's a "structured block" a.k.a. an array. We also copy the numbers 1, 2, 3, 4 and 5 to the appropriate places in the array. Notice the OCaml representation of integers is used. Because this is a structured block, the garbage collector will scan each word in this block, and the GC needs to be able to distinguish between integers and pointers to other heap-allocated blocks (the GC does not have access to type information about this array).
Next the closure ((+) 2) is created. The closure is represented by
this block allocated in the data segment:
.data
.long 3319
.globl Closure__1
Closure__1:
.long caml_curry2
.long 5
.long Closure__fun_58
The header is 3319, indicating a Closure_tag with length 3 words. The
3 words in the block are the address of the function caml_curry2, the
integer number 2 and the address of this function:
.text
.globl Closure__fun_58
Closure__fun_58:
; The function takes two arguments, %eax and %ebx.
; This line causes the function to return %eax + %ebx - 1.
lea -1(%eax, %ebx), %eax
ret
What does this function do? On the face of it, it adds the two
arguments, and subtracts one. But remember that %eax and %ebx are in
the OCaml representation for integers. Let's represent them as:
%eax = 2 * a + 1%ebx = 2 * b + 1
where a and b are the actual integer arguments. So this function
returns:
%eax + %ebx - 1
= 2 * a + 1 + 2 * b + 1 - 1
= 2 * a + 2 * b + 1
= 2 * (a + b) + 1
In other words, this function returns the OCaml integer representation
of the sum a + b. This function is (+)!
(It's actually more subtle than this - to perform the mathematics quickly, OCaml uses the x86 addressing hardware in a way that probably wasn't intended by the designers of the x86.)
So back to our closure - we won't go into the details of the
caml_curry2 function, but just say that this closure is the argument
2 applied to the function (+), waiting for a second argument. Just
as expected.
The actual call to the Array.map function is quite difficult to
understand, but the main points for our examination of OCaml is that the
code:
- Does call
Array.mapwith an explicit closure. - Does not attempt to inline the call and turn it into a loop.
Calling Array.map in this way is undoubtedly slower than writing a
loop over the array by hand. The overhead is mainly in the fact that the
closure must be evaluated for each element of the array, and that isn't
as fast as inlining the closure as a function (if this optimisation were
even possible). However, if you had a more substantial closure than just
((+) 2), the overhead would be reduced. The FP version also saves
expensive programmer time versus writing the imperative loop.
Profiling Tools
There are two types of profiling that you can do on OCaml programs:
- Get execution counts for bytecode.
- Get real profiling for native code.
The ocamlcp and ocamlprof programs perform profiling on bytecode.
Here is an example:
let rec iterate r x_init i =
if i = 1 then x_init
else
let x = iterate r x_init (i - 1) in
r *. x *. (1.0 -. x)
let () =
Random.self_init ();
Graphics.open_graph " 640x480";
for x = 0 to 640 do
let r = 4.0 *. float_of_int x /. 640.0 in
for i = 0 to 39 do
let x_init = Random.float 1.0 in
let x_final = iterate r x_init 500 in
let y = int_of_float (x_final *. 480.) in
Graphics.plot x y
done
done;
Gc.print_stat stdout
And can be run and compiled with
ocamlcp -p a graphics.cma graphtest.ml -o graphtest
./graphtest
ocamlprof graphtest.ml
The comments (* nnn *) are added by ocamlprof, showing how many
times each part of the code was called.
Profiling native code is done using your operating system's native
support for profiling. In the case of Linux, we use gprof. An alternative
is perf, as explained below.
We compile it using the -p option to ocamlopt which tells the
compiler to include profiling information for gprof:
After running the program as normal, the profiling code dumps out a file
gmon.out which we can interpret with gprof:
$ gprof ./a.out
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
10.86 0.57 0.57 2109 0.00 0.00 sweep_slice
9.71 1.08 0.51 1113 0.00 0.00 mark_slice
7.24 1.46 0.38 4569034 0.00 0.00 Sieve__code_begin
6.86 1.82 0.36 9171515 0.00 0.00 Stream__set_data_140
6.57 2.17 0.34 12741964 0.00 0.00 fl_merge_block
6.29 2.50 0.33 4575034 0.00 0.00 Stream__peek_154
5.81 2.80 0.30 12561656 0.00 0.00 alloc_shr
5.71 3.10 0.30 3222 0.00 0.00 oldify_mopup
4.57 3.34 0.24 12561656 0.00 0.00 allocate_block
4.57 3.58 0.24 9171515 0.00 0.00 modify
4.38 3.81 0.23 8387342 0.00 0.00 oldify_one
3.81 4.01 0.20 12561658 0.00 0.00 fl_allocate
3.81 4.21 0.20 4569034 0.00 0.00 Sieve__filter_56
3.62 4.40 0.19 6444 0.00 0.00 empty_minor_heap
3.24 4.57 0.17 3222 0.00 0.00 oldify_local_roots
2.29 4.69 0.12 4599482 0.00 0.00 Stream__slazy_221
2.10 4.80 0.11 4597215 0.00 0.00 darken
1.90 4.90 0.10 4596481 0.00 0.00 Stream__fun_345
1.52 4.98 0.08 4575034 0.00 0.00 Stream__icons_207
1.52 5.06 0.08 4575034 0.00 0.00 Stream__junk_165
1.14 5.12 0.06 1112 0.00 0.00 do_local_roots
[ etc. ]
Using perf on Linux
Assuming perf is installed and your program is compiled into
native code with -g (or ocamlbuild tag debug), you just need to type
perf record --call-graph=dwarf -- ./foo.native a b c d
perf report
The first command launches foo.native with arguments a b c d and
records profiling information in perf.data; the second command
starts an interactive program to explore the call graph. The option
--call-graph=dwarf makes perf aware of the calling convention of
OCaml (with old versions of perf, enabling frame pointers in OCaml
might help; opam provides suitable compiler switches, such as 4.02.1+fp).
Using Instruments on macOS
macOS ships with a performance monitoring and debugging application called
Instruments that comes with a CPU counter, a Time Profiler, and a System
Trace templates.
Once you launch it and select the template you want, you must start recording before you launch your application.
As you launch your application, real-time results will appear listed in Instrument's browser:
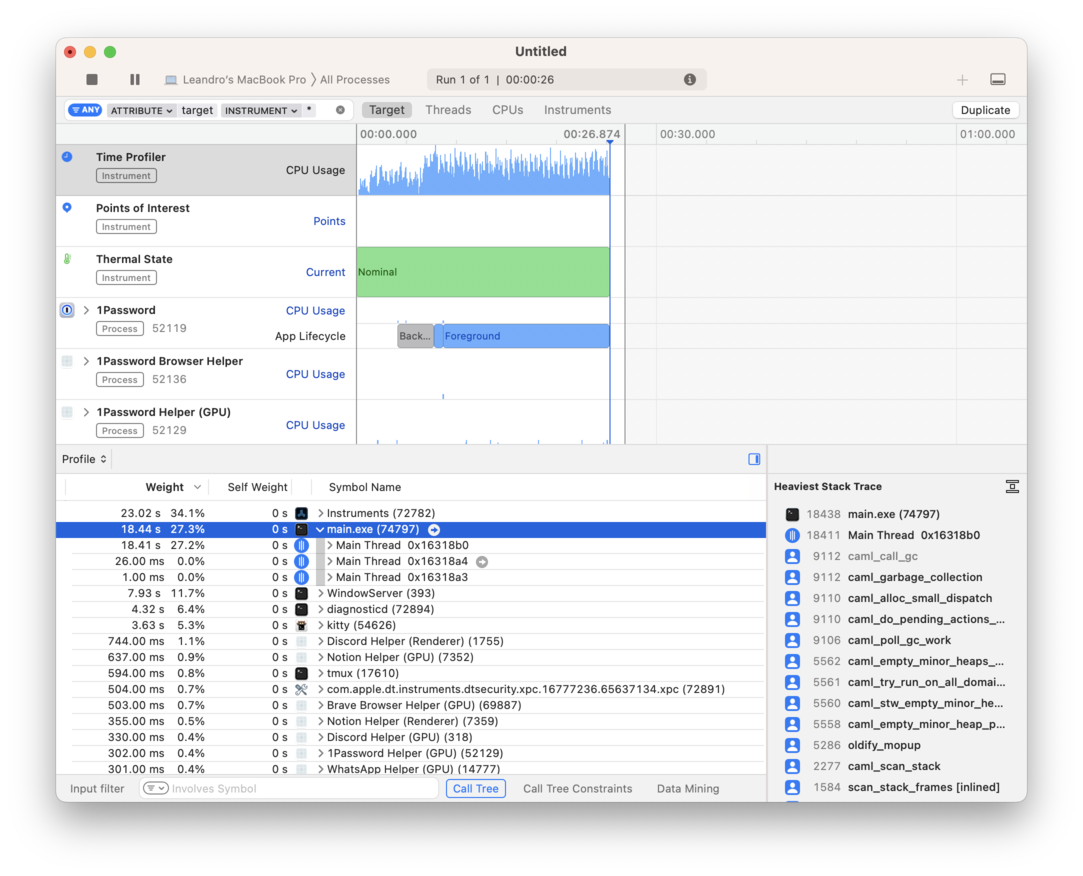
From there, you can click on your program there and dig to see which functions are taking the longest to execute.
Summary
In summary here are some tips for getting the best performance out of your programs:
- Write your program as simply as possible. If it takes too long to run, profile it to find out where it's spending its time and concentrate optimisations on just those areas.
- Check for unintentional polymorphism, and add type hints for the compiler.
- Closures are slower than simple function calls, but add to maintainability and readability.
- As a last resort, rewrite hotspots in your program in C (but first check the assembly language produced by the OCaml compiler to see if you can do better than it).
- Performance might depend on external factors (speed of your database queries? speed of the network?). If so then no amount of optimization will help you.
Further Reading
You can find out more about how OCaml represents different types by
reading the ("Interfacing C with OCaml") chapter in the OCaml manual and also
looking at the mlvalues.h header file.
Help Improve Our Documentation
All OCaml docs are open source. See something that's wrong or unclear? Submit a pull request.